一、引言
本文介绍如何使用三台虚拟机,搭建出 Hadoop 大数据平台。
建议使用文章内提供的链接下载软件,或者自行下载相同版本的软件,版本不同可能会出现问题。下载软件时尽量使用迅雷等软件在主机中下载好再传输到虚拟机中,这样比较快,不建议直接在虚拟机中下载。
注:以下命令中, “#”后面的语句是使用 root 执行的,“$”后面的 语句是使用普通用户(之后创建的用户hadoop)执行的。
二、安装虚拟机
2.1 下载CentOS镜像
http://mirrors.aliyun.com/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1511.iso
2.2 安装
打开 VMware ,点击创建虚拟机,选择刚刚的系统镜像。网络模式要选择NAT,内存大小根据自己情况设置,其他的都默认即可。
具体安装过程:
1. 选择 Install CentOS7,选择 English->continue。
2. DATE&TIME,Region 选择 Asia,City 选择 Shanghai,左上角 Done。
3. INSTALLATION DESTINATION,点进去后直接点左上角的 Done。
4. NETWORK & HOST NAME,网卡右侧选择 ON。如果出现了IP地址,记住它的IP地址。下面的 Host name 改为 cluster1,左上角 Done。
5. 点击右下角 Begin installation。
6. 设置 root 密码。
7. 右侧 user creation,Full name 设置为 cluster1,密码随意,不要选择 make this user administrator。
8. 待下方进度条结束后,会有 reboot 这个选项,点击重启后,即可登陆。
再安装两台这样的虚拟机,对应的名字分别设置为 cluster2 和 cluster3 即可。
三、准备工作
3.1 关闭防火墙和Selinux
我们安装的 centOS 最小版没有防火墙,在其他 centOS 上操作时必须要关闭防火墙。如果是使用上面链接下载的系统镜像,在这里就只需要关闭Selinux就行了。
每台都要执行
// 编辑 Selinux 配置文件
# vi /etc/selinux/config
//将 SELINUX 设置为 disabled 即: SELINUX=disabled
# reboot
// 重启机器后 root 用户查看 Selinux 状态
# getenforce
注意,修改配置的时候看清楚,不要修改 SELINUXTYPE,如果你不小心修改了 SELINUXTYPE 导致重启后无法进入系统,则按照下面进行操作。
1. 重启时在启动页面,在第一行 按 E, 进入 grub 编辑页面。
2. 向下翻页,找到 linux16 那一行,在language 后面 也就是LANG=zh_CN.UTF-8,空格 加上 selinux=0
3. 然后按ctrl + x 启动,就可以成功进入系统。
4. 再重新修改selinux配置文件即可
SELINUX=disabled
SELINUXTYPE=targeted
3.2 使用WinSCP进行文件传输
在主机上下载一个支持SFTP协议的文件传输软件,比如 WinSCP, Filezilla,用于向虚拟机内传输文件。
3.3 使用SSH进行连接(可选)
打开主机的命令行(Windows, Linux, Mac都可),输入以下命令。
ssh root@192.168.142.133
后面这个ip地址改成你的虚拟机的ip地址,可以在虚拟机中使用ip addr命令进行查询。
使用同样的办法搞定其他两台虚拟机。这样做的目的是方便进行文字的复制粘贴,不必每次都手动输入命令。
3.4 修改 hosts
每台都要执行
# vi /etc/hosts
// 在最下面添加以下内容,ip 地址改成你的 ip 地址
192.168.142.133 cluster1
192.168.142.134 cluster2
192.168.142.135 cluster3
可以在虚拟机里使用 ip addr 查看ip地址
3.5 检查网络是否正常
在 cluster1 上 输入 ping cluster2,观察是否可以正常通信。
3.6 安装软件
以下软件是安装时需要的依赖环境,安装 MySQL 时需要使用 perl 和 libaio,ntpdate 负责集群内服务器 时间,screen 用于新建后台任务。
每台都要执行
# yum install perl*
# yum install ntpdate
# yum install screen
3.7 新建用户hadoop
每台都要执行
新建用户hadoop,这个用户专门用来维护集群,因为实际中使用 root 用户的机会很少,而且不安全。
//创建用户组
# groupadd hadoop
//创建用户
# useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
//设置密码
# passwd hadoop
3.8 生成 ssh 密钥并分发
只在 cluster1 上执行
// 生成 ssh 密钥, 切换到 hadoop 用户 $ ssh-keygen -t rsa 然后一路回车
//切换到用户hadoop
# su hadoop
ssh-keygen -t rsa ssh-copy-id cluster1
ssh-copy-id cluster2 ssh-copy-id cluster3
3.9 安装 NTP 服务
cluster1 上执行以下操作
//切换到root
$ exit
// 安装 ntp
# yum install ntp
# vi /etc/ntp.conf
// 注释掉以下 4 行,也就是在这 4 行前面加#
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
//最下面加入以下内容,分别为网关和掩码
restrict default ignore
restrict 网关 mask 子网掩码 nomodify notrap
server 127.127.1.0
网关一般是主机的IP地址,子网掩码一般是255.255.255.0
可以在主机中看到,如果是Windows ,输入 ipconfig 即可
我查询到的内容如下:
Ethernet adapter VMware Network Adapter VMnet8:
Connection-specific DNS Suffix . :
Link-local IPv6 Address . . . . . : fe80::c9b3:9065:b9d0:aaca%19
IPv4 Address. . . . . . . . . . . : 192.168.142.1
Subnet Mask . . . . . . . . . . . : 255.255.255.0
Default Gateway . . . . . . . . . :
因此,我在这里的网关和子网掩码分别填写192.168.142.1和255.255.255.0
继续在cluster1中执行命令
// 重启 ntp 服务
# service ntpd restart
// 设置 ntp 服务器开机自动启动
# chkconfig ntpd on
以下为客户端的配置(除 cluster1 外其他所有的机器,即 cluster2 和 cluster3): 设定每天 00:00 向服务器同步时间,并写入日志
# crontab -e
//输入以下内容后保存并退出:
0 0 * * * /usr/sbin/ntpdate cluster1>> /root/ntpd.log
// 手动同步时间
# ntpdate cluster1
四、安装 MySQL
4.1 下载
https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
使用 WinSCP 传输到 cluster2 的 /usr/local/ 目录下
4.2 安装
只在 cluster2 上进行安装,因为我们的集群中,只有 cluster2 上需要安装一个 MySQL。
# yum remove mysql mysql-server mysql-libs compat-mysql51
# rm -rf /var/lib/mysql
# rm -rf /etc/my.cnf
# cd /usr/local
//解压
# tar -zxvf mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
// 改名为 mysql
# mv mysql-5.6.37-linux-glibc2.12-x86_64 mysql
// 删除安装包
# rm mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
// 修改环境变量
# vi /etc/profile
//在最下面添加
export MYSQL_HOME=/usr/local/mysql
export PATH=MYSQL_HOME/bin:PATH
// 刷新环境变量
# source /etc/profile
// 新建用户组mysql
# groupadd mysql
//新建用户
# useradd -r -g mysql -s /bin/false mysql
# cd /usr/local/mysql
# chown -R mysql:mysql .
# scripts/mysql_install_db --user=mysql
// 修改当前目录拥有者为 root 用户
# chown -R root .
// 修改当前 data 目录拥有者为 mysql 用户
# chown -R mysql data
# bin/mysqld_safe --user=mysql &
# cd /usr/local/mysql
// 登陆 mysql
# bin/mysql
// 登陆成功后退出即可
mysql> exit;
// 进行 root 账户密码的修改等操作
# bin/mysql_secure_installation
//首先要求输入 root 密码,由于我们没有设置过 root 密码,括号里面说了,如果没有 root 密码就直接按回车。 是否设定 root 密码,选 y,设定密码为 cluster,是否移除匿名用户:y。然后有个是否关闭 root 账户的远程 登录,选 n,删除 test 这个数据库?y,更新权限?y,然后 ok。
# cp support-files/mysql.server /etc/init.d/mysql.server
// 查看 mysql 的进程号
# ps -ef | grep mysql
// 如果有的话就 kill 掉,保证 mysql 已经中断运行了,一般 kill 掉/usr/local/mysql/bin/mysqld 开头的即可
# kill 进程号
// 启动 mysql
# /etc/init.d/mysql.server start -user=mysql
//切换用户
# su hadoop
//配置一下访问权限:
$ mysql -u root -p
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'cluster' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
关闭 mysql 的指令(不需要执行)
# mysqladmin -u root -p shutdown
五、安装 JDK
5.1 下载
https://download.oracle.com/otn/java/jdk/7u80-b15/jdk-7u80-linux-x64.tar.gz
使用 WinSCP 传输到 cluster1 的 /usr/local/ 目录下
5.2 安装
cluster1中执行
# cd /usr/local/
# tar -zxvf jdk-7u80-linux-x64.tar.gz
// 复制 jdk 到其他的服务器上
# scp -r /usr/local/jdk1.7.0_80/ cluster2:/usr/local/
# scp -r /usr/local/jdk1.7.0_80/ cluster3:/usr/local/
三台虚拟机都要执行
# vi /etc/profile
// 添加以下内容
export JAVA_HOME=/usr/local/jdk1.7.0_80/
export JRE_HOME=/usr/local/jdk1.7.0_80/jre
export CLASSPATH=.:JAVA_HOME/lib:JRE_HOME/lib:CLASSPATH
export PATH=JAVA_HOME/bin:JRE_HOME/bin:JAVA_HOME:$PATH
5.3 测试
$ java -version
看到版本信息则表示OK了,如下所示
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
六、安装 ZooKeeper
6.1 下载
http://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
使用 WinSCP 传输到 cluster1 的 /usr/local/ 目录下
6.2 安装
cluster1中执行
# cd /usr/local/
# tar -zxvf zookeeper-3.4.6.tar.gz
# vi /etc/profile
// 添加以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=ZOOKEEPER_HOME/bin:PATH
# cd /usr/local/zookeeper-3.4.6
// 在 conf 中新建 zoo.cfg 文件
# vi conf/zoo.cfg
输入以下内容
# 客户端心跳时间(毫秒)
tickTime=2000
# 允许心跳间隔的最大时间
initLimit=10
# 同步时限
syncLimit=5
# 数据存储目录
dataDir=/home/hadoop_files/hadoop_data/zookeeper
# 数据日志存储目录
dataLogDir=/home/hadoop_files/hadoop_logs/zookeeper/dataLog
# 端口号
clientPort=2181
# 集群节点和服务端口配置
server.1=cluster1:2888:3888
server.2=cluster2:2888:3888
server.3=cluster3:2888:3888
继续在cluster1中执行
// 创建 zookeeper 的数据存储目录和日志存储目录
# mkdir -p /home/hadoop_files/hadoop_data/zookeeper
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/dataLog
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/logs
// 修改文件夹的权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/zookeeper-3.4.6
// 在 cluster1 号服务器的 data 目录中创建一个文件 myid,输入内容为 1
// myid 应与 zoo.cfg 中的集群节点相匹配
# echo "1" >> /home/hadoop_files/hadoop_data/zookeeper/myid
// 修改 zookeeper 的日志输出路径(注意 CDH 版与原生版配置文件不同)
# vi bin/zkEnv.sh
// 将配置文件里面的对应项的值替换为以下内容
if [ "x{ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/home/hadoop_files/hadoop_logs/zookeeper/logs"
fi
if [ "x{ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
继续在cluster1中执行
// 修改 zookeeper 的日志配置文件
# vi conf/log4j.properties
// 将配置文件里面的对应项的值替换为以下内容
zookeeper.root.logger=INFO, ROLLINGFILE
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender
//将这个 zookeeper-3.4.6 的目录复制到其他的两个节点上
# scp -r /usr/local/zookeeper-3.4.6 cluster2:/usr/local/
# scp -r /usr/local/zookeeper-3.4.6 cluster3:/usr/local/
// 切换到 hadoop 用户
# su hadoop
// 刷新环境变量
source /etc/profile
// 启动 zookeeper zkServer.sh start
在cluster2中执行,切换到root
# vi /etc/profile
//添加以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=ZOOKEEPER_HOME/bin:PATH
// 创建 zookeeper 的数据存储目录和日志存储目录
# mkdir -p /home/hadoop_files/hadoop_data/zookeeper
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/dataLog
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/logs
// 添加 myid
# echo "2" >> /home/hadoop_files/hadoop_data/zookeeper/myid
// 修改文件夹的权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/zookeeper-3.4.6
// 切换到 hadoop 用户
# su hadoop
// 刷新环境变量
source /etc/profile
// 启动 zookeeper zkServer.sh start
cluster3中执行和cluster2中相同的操作,只要把myid中的2改成3即可。
三台虚拟机都要执行
//三台 zookeeper 都启动后,使用 jps 命令查看进程是否启动
jps
可以看到一个叫 QuorumPeerMain 的进程,说明 zookeeper 启动成功
// 查看 zookeeper 状态 zkServer.sh status
可以看到三台中有一个是 leader,两个是 follower,如下
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
关闭 zookeeper 的命令 (关机前在每台上都要执行,这里不需要执行)
$ zkServer.sh stop
七、安装 Kafka
7.1 下载
http://archive.apache.org/dist/kafka/0.8.2.1/kafka_2.10-0.8.2.1.tgz
使用 WinSCP 传输到 cluster1 的 /usr/local/ 目录下
7.2 安装
三台虚拟机都要执行
# vi /etc/profile
//添加环境变量
export KAFKA_HOME=/usr/local/kafka_2.10-0.8.2.1
export PATH=KAFKA_HOME/bin:PATH
cluster1中执行
# cd /usr/local/
# tar -zxvf kafka_2.10-0.8.2.1.tgz
// 修改配置文件
# vi /usr/local/kafka_2.10-0.8.2.1/config/server.properties
// 修改下面几项
// 第一项
broker.id=1
// 第二项:此处要写对应机器的 ip 地址(注意把前面的注释符号#删掉)
host.name=192.168.142.133
advertised.host.name=192.168.142.133
// 第三项:修改日志路径
log.dirs=/home/hadoop_files/hadoop_logs/kafka
// 第四项:此处要写 zookeeper 集群的 ip+端口号,逗号隔开
zookeeper.connect=cluster1:2181,cluster2:2181,cluster3:2181
//修改完环境变量,更新配置文件
# source /etc/profile
// 保存退出后创建 logs 文件夹
# mkdir -p /home/hadoop_files/hadoop_logs/kafka
// 修改权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/kafka_2.10-0.8.2.1
// 复制文件夹
# scp -r /usr/local/kafka_2.10-0.8.2.1 cluster2:/usr/local/
# scp -r /usr/local/kafka_2.10-0.8.2.1 cluster3:/usr/local/
cluster2 上
# vi /usr/local/kafka_2.10-0.8.2.1/config/server.properties
//修改如下内容
broker.id=2
host.name=192.168.142.134
advertised.host.name=192.168.142.134
// 保存退出后创建 logs 文件夹
# mkdir -p /home/hadoop_files/hadoop_logs/kafka
// 修改权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/kafka_2.10-0.8.2.1
cluster3 上
# vi /usr/local/kafka_2.10-0.8.2.1/config/server.properties
broker.id=3
host.name=192.168.142.135
advertised.host.name=192.168.142.135
// 保存退出后创建 logs 文件夹
# mkdir -p /home/hadoop_files/hadoop_logs/kafka
// 修改权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/kafka_2.10-0.8.2.1
使用 hadoop 用户启动 kafka 集群
先启动 zookeeper 集群,然后在 kafka 集群中的每个节点执行下面命令
三台虚拟机都要执行
# su hadoop
source /etc/profile kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
启动完成后按回车即可
7.3 测试
cluster1上使用用户hadoop执行
// 创建 topic
kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --partitions 1 --topic mykafka
// 查看 Topic kafka-topics.sh --list --zookeeper cluster1:2181,cluster2:2181,cluster3:2181
//此时会显示 Topic:mykafka
// 查看详细信息
$ kafka-topics.sh --describe --zookeeper cluster1:2181,cluster2:2181,cluster3:2181
发送消息(cluster1 上执行)
//注意不要将cluster1:9092写成localhost:9092,除非手动修改了hosts值
$ kafka-console-producer.sh --broker-list cluster1:9092 --topic mykafka
接收消息(cluster2 上执行)
$ kafka-console-consumer.sh -zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --topic mykafka --from-beginning
// 在 cluster1 输入任意文字
Hello World!
可以在 cluster2 上看到相应的信息 按 Ctrl+C 退出
八、安装 Hadoop
8.1 下载
http://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
使用 WinSCP 传输到 cluster1 的 /usr/local/ 目录下
8.2 安装
cluster1中执行
# cd /usr/local/
# tar -zxvf hadoop-2.6.5.tar.gz
# cd hadoop-2.6.5/etc/hadoop
# vi hadoop-env.sh
//修改对应属性为下面的值
export JAVA_HOME=/usr/local/jdk1.7.0_80
export HADOOP_PID_DIR=/home/hadoop_files
// 配置 mapred-env.sh
# vi mapred-env.sh
export HADOOP_MAPRED_PID_DIR=/home/hadoop_files
配置 core-site.xml 文件
# vi core-site.xml
<configuration>
<!-- 指定 hdfs 的 nameservices 名称为 mycluster,与 hdfs-site.xml 的 HA 配置相同 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1:9000</value>
</property> <!-- 指定缓存文件存储的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_files/hadoop_tmp/hadoop/data/tmp</value>
</property>
<!-- 配置 hdfs 文件被永久删除前保留的时间(单位:分钟),默认值为 0 表明垃圾回收站功能关闭 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property> <!-- 指定 zookeeper 地址,配置 HA 时需要 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>cluster1:2181,cluster2:2181,cluster3:2181</value>
</property>
</configuration>
配置 hdfs-site.xml 文件
# vi hdfs-site.xml
<configuration>
<!-- 指定 hdfs 元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop_files/hadoop_data/hadoop/namenode</value>
</property>
<!-- 指定 hdfs 数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop_files/hadoop_data/hadoop/datanode</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>cluster1:50090</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启 WebHDFS 功能(基于 REST 的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置 mapred-site.xml 文件
# vi mapred-site.xml
<configuration>
<!-- 指定 MapReduce 计算框架使用 YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定 jobhistory server 的 rpc 地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>cluster1:10020</value>
</property>
<!-- 指定 jobhistory server 的 http 地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cluster1:19888</value>
</property>
</configuration>
配置 yarn-site.xml 文件
# vi yarn-site.xml
<configuration>
<!-- NodeManager 上运行的附属服务,需配置成 mapreduce_shuffle 才可运行 MapReduce 程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置 Web Application Proxy 安全代理(防止 yarn 被攻击) -->
<property>
<name>yarn.web-proxy.address</name>
<value>cluster2:8888</value>
</property> <!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志删除时间为 7 天,-1 为禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 修改日志目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/home/hadoop_files/hadoop_logs/yarn</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cluster1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>cluster1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>cluster1:8031</value>
</property>
</configuration>
配置 slaves 文件
# vi slaves
删除 localhost,添加以下内容:
cluster1
cluster2
cluster3
// 将 cluster1 的 hadoop 工作目录同步到集群其它节点
scp -r /usr/local/hadoop-2.6.5 cluster2:/usr/local/ scp -r /usr/local/hadoop-2.6.5 cluster3:/usr/local/
在三台虚拟机上执行
# mkdir -p /home/hadoop_files/hadoop_data/hadoop/namenode
# mkdir -p /home/hadoop_files/hadoop_data/hadoop/datanode
# mkdir -p /home/hadoop_files/hadoop_tmp/hadoop/data/tmp
# mkdir -p /home/hadoop_files/hadoop_logs/yarn
# chown -R hadoop:hadoop /home/hadoop_files/
# chown -R hadoop:hadoop /usr/local/hadoop-2.6.5/
# vi /etc/profile
//添加以下内容
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export LD_LIBRARY_PATH=HADOOP_HOME/lib/native
export PATH=HADOOP_HOME/bin:HADOOP_HOME/sbin:PATH
三台虚拟机都要执行,切换到hadoop用户。
Hadoop 启动的先决条件是 zookeeper 已经成功启动。
// 使修改的环境变量生效
source /etc/profile
// 启动 zookeeper 集群(分别在 cluster1, cluster2 和 cluster3 上执行) zkServer.sh start
//接下来开始格式化:
// 启动 journalnode(在所有 datanode 上执行,也就是 cluster1, cluster2, cluster3)
hadoop-daemon.sh start journalnode
//启动后使用 jps 命令可以看到 JournalNode 进程
// 格式化 HDFS(在 cluster1 上执行) hdfs namenode -format
// 格式化完毕后可关闭 journalnode(在所有 datanode 上执行)
hadoop-daemon.sh stop journalnode
// 启动 HDFS(cluster1 上) start-dfs.sh
// 启动后 cluster1 上使用 jps 可以看到 NameNode, DataNode, SecondaryNameNode cluster2 和 cluster3 上可以看到 DataNode
jps
// 启动 YARN(cluster1 上) start-yarn.sh
// 启动后 cluster1 上使用 jps 可以看到 NodeManager, ResourceManager cluster2 和 cluster3 上可以看到 NodeManager
$ jps
以下两条命令是关闭 YARN 和 HDFS 的命令,重启服务器或关机前一定要执行,否则有可能导致数据或服务损坏。
// 关闭 YARN 的命令(cluster1 上)
stop-yarn.sh
// 关闭 HDFS 的命令(cluster1 上) stop-dfs.sh
8.3 测试
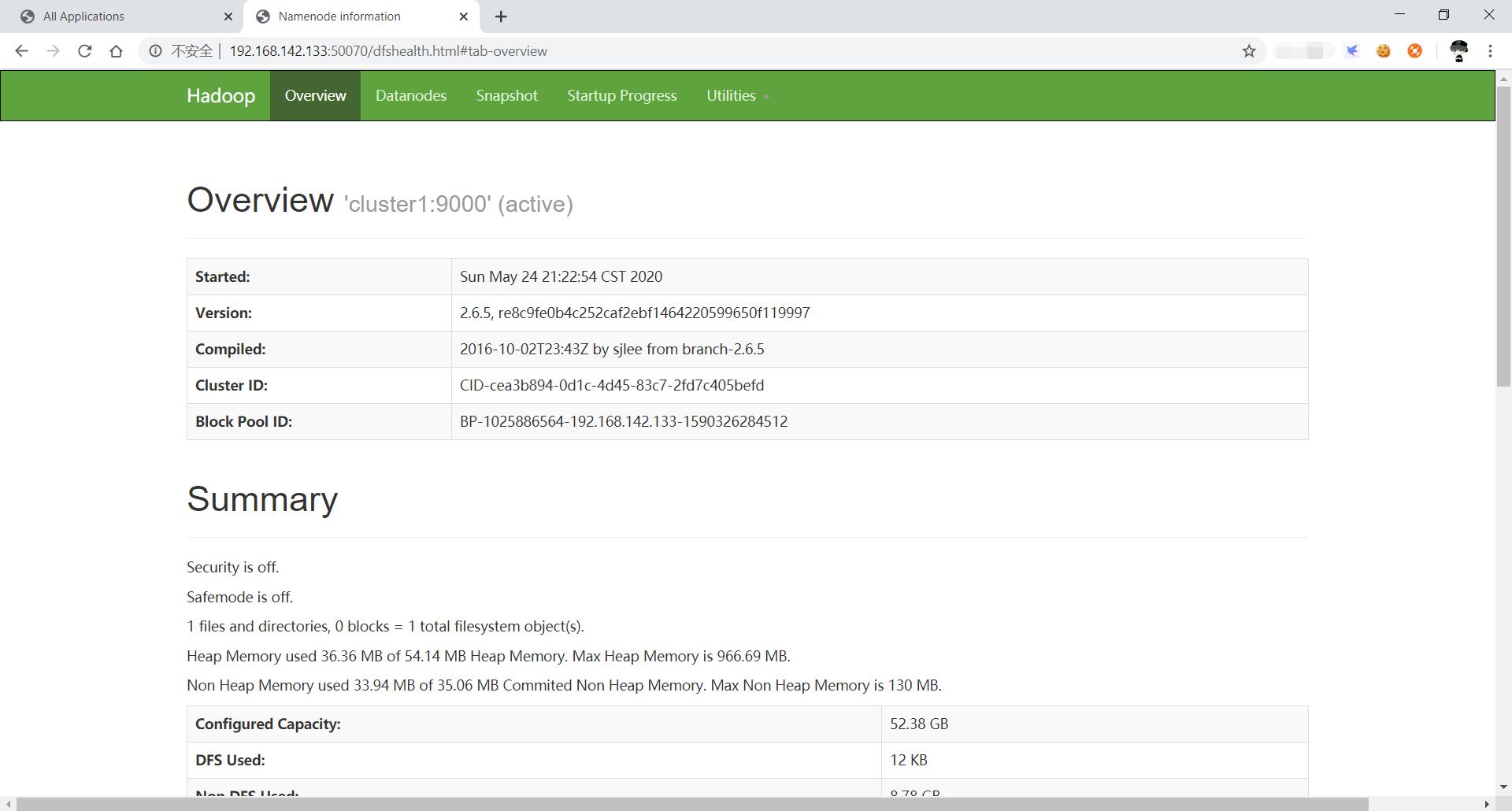
启动 HDFS 后,可以在浏览器中(不要使用edge),打开 192.168.142.133:50070,可以看到 HDFS 的 web 界面
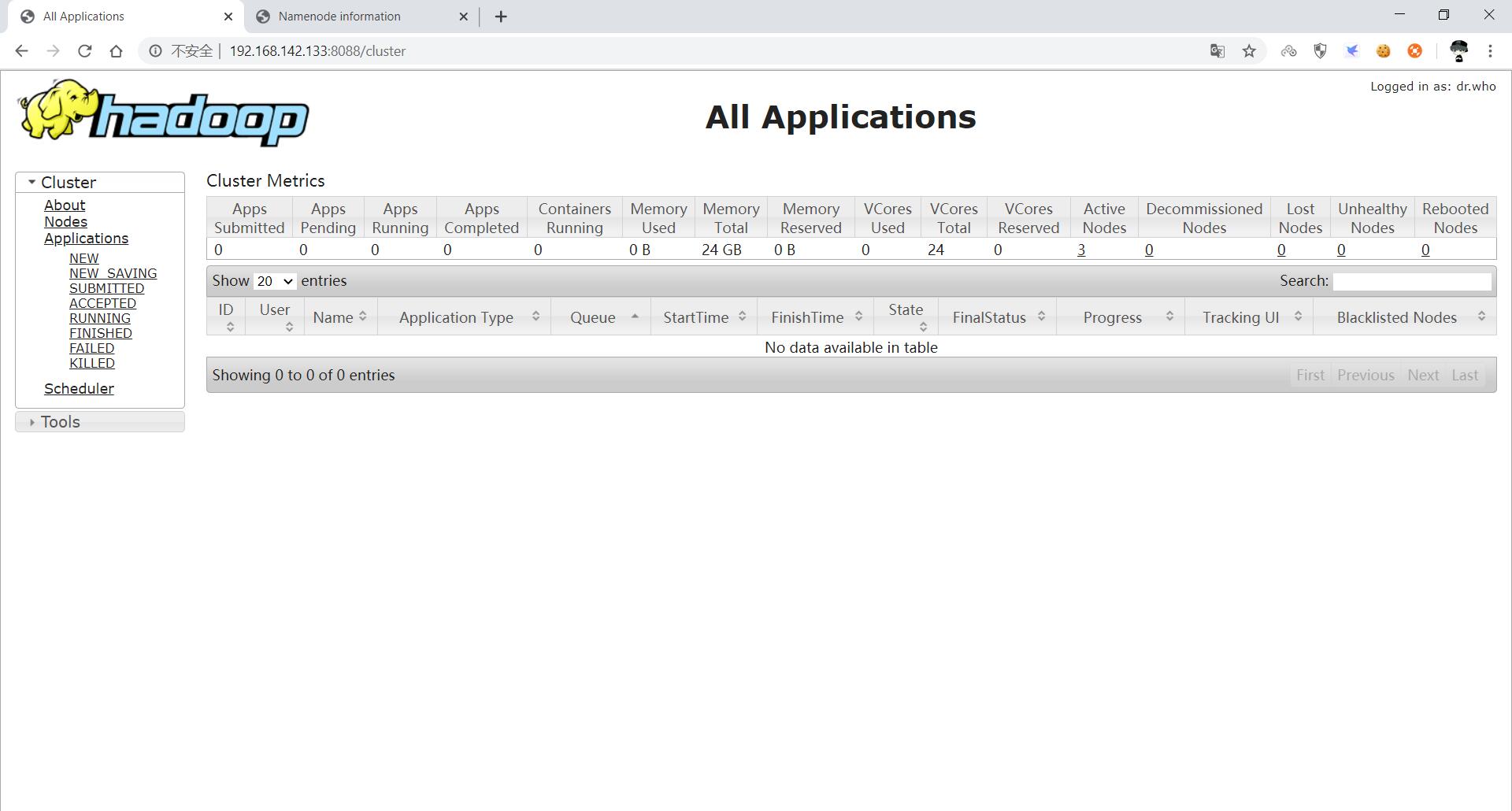
启动 YARN 后,可以通过浏览器访问 192.168.56.121:8088,查看 YARN 的 web 界面。
命令行测试:
在 cluster1 中
// 切换至 hadoop 用户的主目录
cd ~
// 新建一个测试文件 vi testfile
// 输入
ghb123
// 保存退出
// 查看 HDFS 根目录的文件
hdfs dfs -ls /
// 在 HDFS 的根目录创建 test 目录 hdfs dfs -mkdir /test
如果出现了 mkdir: Cannot create directory /test. Name node is in safe mode说明 HDFS 刚启动不久,还在安全检查中。由于我们的笔记本性能不够强,安全检查的时间会很长,可以使用命令退出安全模式$ hdfs dfsadmin -safemode leave
// 创建完文件夹后再次查看根目录,查看目录是否新建成功
hdfs dfs -ls /
// 将测试文件 testfile 上传至 HDFS 根目录下的 test 目录中 hdfs dfs -put testfile /test
// 在 cluster2 上 // 切换至 hadoop 用户的主目录
cd ~/
// 查看 HDFS 根目录 hdfs dfs -ls /
// 查看 HDFS 根目录下的 test 目录,可以看到我们刚才在 cluster1 上上传的文件 testfile
hdfs dfs -ls /test
// 查看 HDFS 上的/test/testfile 文件的内容 hdfs dfs -cat /test/testfile
// 将 HDFS 上的/test/testfile 下载到本地
hdfs dfs -get /test/testfile
// 查看本地当前目录内的内容,可以看到刚才下载的 testfile ls
太强了