1 实验目的
- 了解Kafka中的生产者、消费者、topic等基本概念;
- 熟悉Kafka Shell常用命令;
- 学习使用Kafka的Java API,编程实现Kafka常用功能;
2 实验环境
实验平台:基于实验一搭建的虚拟机Hadoop大数据实验平台上的Kafka集群;
编程语言:JAVA(推荐使用)、Python、C++等;
3 实验内容
- 使用Kafka Shell命令完成以下任务:
(1). 创建任意topic
(2). 创建向该topic发送数据的生产者
(3). 创建订阅该topic的消费者 - 使用Java API编程实现以下任务:
(1). 实现生产者程序,向指定topic发送数据
(2). 实现消费者程序,从(1)中指定的topic中订阅数据并将消费得到的数据存到本地文件中。 - 对以上两部分任务撰写实验报告,并提交实验代码。
4 准备工作
//三台都要执行
//切换到用户hadoop
su hadoop
//启动zookeeper
zkServer.sh start
//启动kafka
kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
5 Kafka Shell命令
5.1 创建任意topic
kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --partitions 1 --topic ghb123
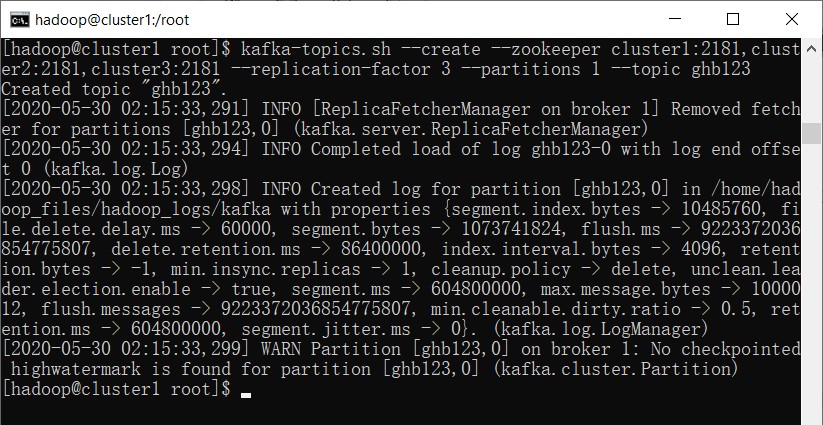
5.2 创建向该topic发送数据的生产者
在cluster1上执行
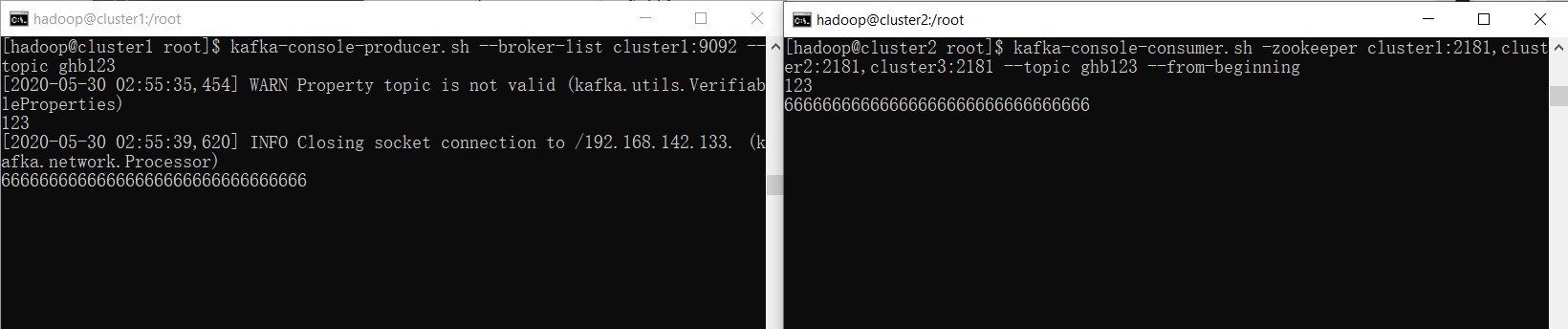
kafka-console-producer.sh --broker-list cluster1:9092 --topic ghb123
注意,这里的cluster1:9092如果写成localhost:9092可能会出现错误,除非事先将localhost的ip指向修改为了当前ip。
5.3 创建订阅该topic的消费者
在cluster2上执行
kafka-console-consumer.sh -zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --topic ghb123 --from-beginning
5.4 验证效果
在cluster1中输入内容,可以在cluster2中显示出来。
6 Java API
6.1 实现生产者程序,向指定topic发送数据
编写程序ghbProducer.java
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import java.util.Scanner;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class ghbProducer {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "cluster1:9092");
Producer<Integer, String> producer = new Producer<Integer, String>(new ProducerConfig(props));
String topic;
System.out.print("请输入topic名称:");
topic = in.next();
File file = new File("kafka采集数据实验.txt");
BufferedReader reader = null;
System.out.print("请输入发送数据行数:");
int num = in.nextInt();
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) {
producer.send(new KeyedMessage<Integer, String>(topic, tempString));
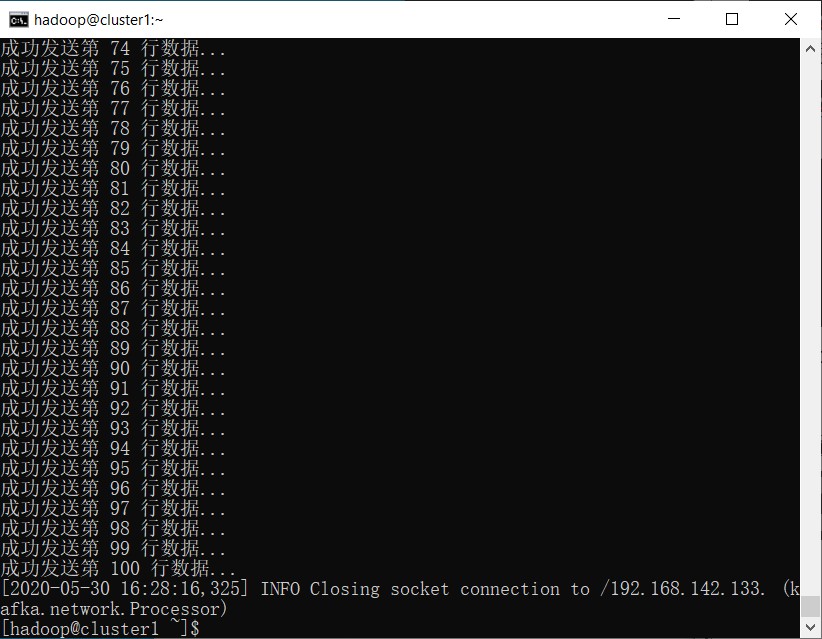
System.out.println("成功发送第 " + line + " 行数据...");
if (line == num)
break;
line++;
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
producer.close();
}
}
打开WinSCP,将ghbProducer.java及实验数据复制到虚拟机cluster1的/home/hadoop路径下。
// 编译
javac -cp /usr/local/kafka_2.10-0.8.2.1/libs/*: ghbProducer.java
// 运行
java -cp /usr/local/kafka_2.10-0.8.2.1/libs/*: ghbProducer
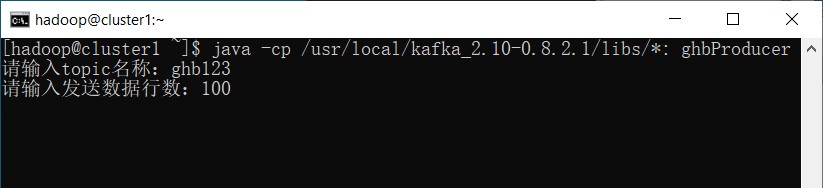
输入topic名称以及发送的行数。
6.2 实现消费者程序,从指定的topic中订阅数据并将消费得到的数据存到本地文件中。
编写程序ghbConsumer.java
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.Scanner;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class ghbConsumer {
public static void main(String[] args) {
try {
Scanner in = new Scanner(System.in);
String topic, path;
System.out.print("请输入topic名称:");
topic = in.next();
System.out.print("保存至文件:");
path = in.next();
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
int i = 1;
while (it.hasNext()) {
BufferedWriter bw = new BufferedWriter(new FileWriter(path, true));// 追加
String out = new String(it.next().message());
bw.write(out + '\n');
System.out.println("消费第" + i + "行数据 " + out);
i++;
bw.close();
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("group.id", "group1");
props.put("zookeeper.connect", "cluster1:2181,cluster2:2181,cluster3:2181");
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
}
打开WinSCP,将ghbConsumer.java复制到虚拟机cluster2的/home/hadoop路径下。
// 编译
javac -cp /usr/local/kafka_2.10-0.8.2.1/libs/*: ghbConsumer.java
// 运行
java -cp /usr/local/kafka_2.10-0.8.2.1/libs/*: ghbConsumer
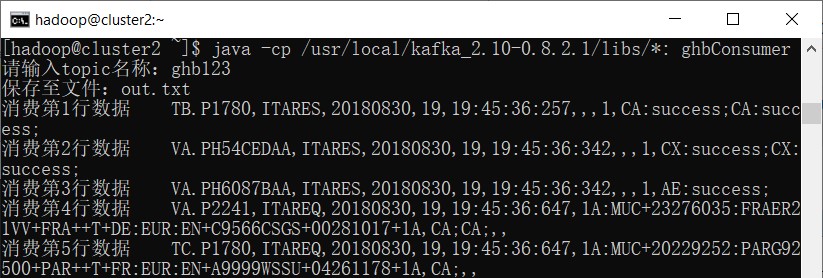
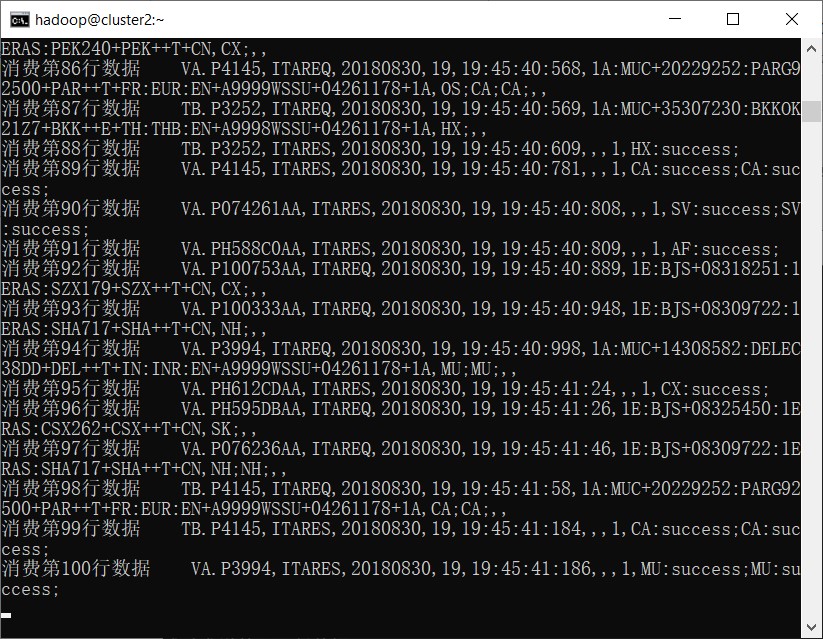
输入topic名称和保存文件的路径。
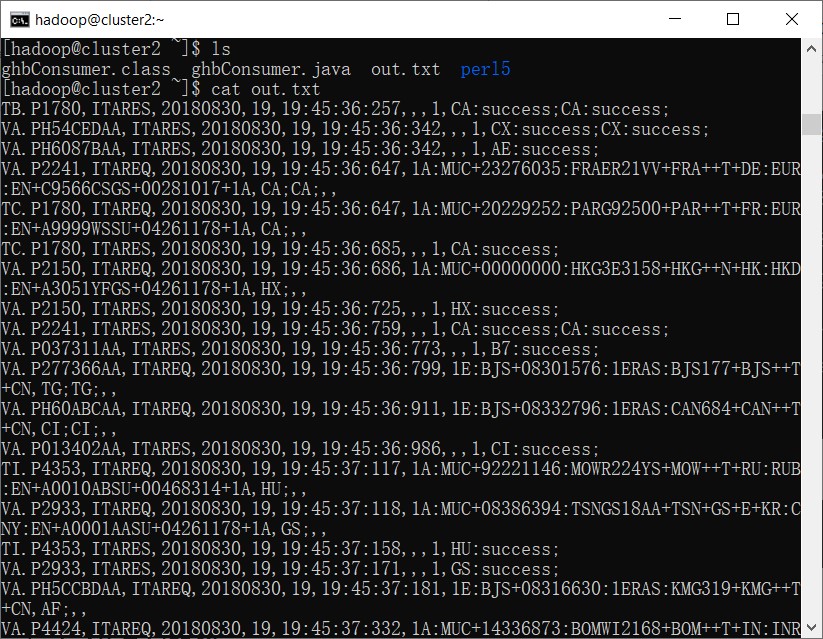
查看保存的文件
ls
cat out.txt
7 关机前操作
//停止kafka
kafka-server-stop.sh
//停止zookeeper
zkServer.sh stop
能上传下实验5参考下吗0.0
好的,已发布
感谢!